DataLens 使用手册
了解如何使用 DataLens Chat Agent 和浏览器插件完成网页采集、数据分析、报告生成和结果下载。
DataLens 有两种主要使用方式:
- Chat Agent:你用自然语言提出采集、清洗、分析、报告需求,DataLens 自动完成网页采集、数据整理和文件生成。
- 浏览器插件:你在网页上直接选择要采集的表格或列表,编辑字段,配置详情页下钻,然后导出结果。
如果你已经知道要采集哪个网页、要哪些字段,优先用 Chat Agent。
如果你想亲自确认页面上哪一块数据会被采集,优先用浏览器插件。
1. 浏览器插件:所见即所得采集
浏览器插件适合采集你正在浏览的页面,例如商品列表、评论列表、招聘列表、商家目录、文章列表等。
1.1 安装与初始化
第一步:下载插件
你可以从 Chrome Web Store 或 Microsoft Edge Add-ons 安装 DataLens。
如果应用提示你安装或更新 DataLens 浏览器插件,优先使用与你当前浏览器匹配的安装入口。Chrome 用户用 Chrome Web Store,Edge 用户用 Edge Add-ons。
如果你所在的环境无法访问浏览器应用商店,也可以下载 DataLens 备用安装包。下载后按照 Chrome 官方的加载未打包扩展程序说明 完成手动安装。
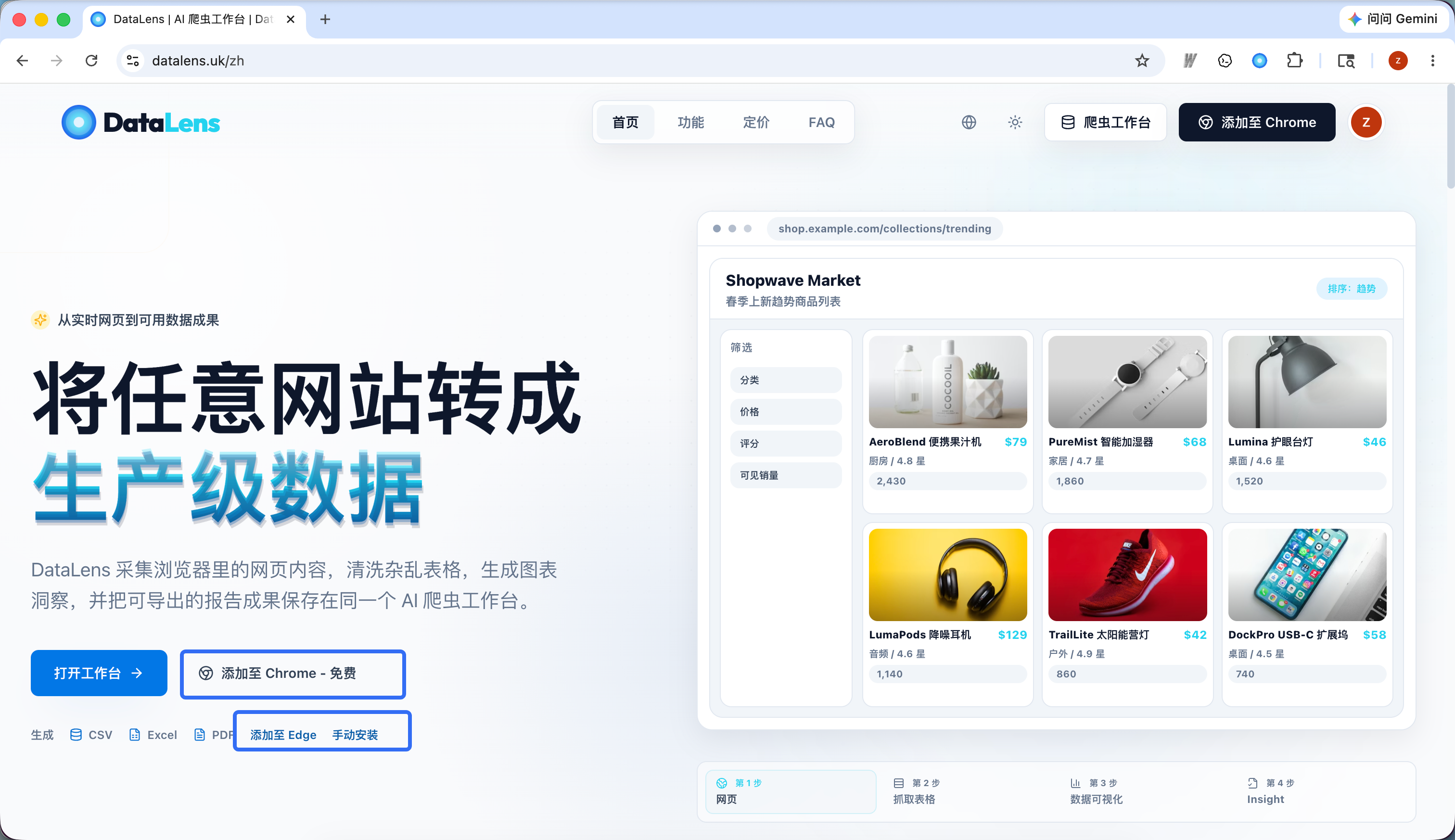
第二步:固定到浏览器工具栏
安装完成后,建议把 DataLens 固定到浏览器工具栏:
- 点击浏览器右上角的扩展图标。
- 找到 DataLens。
- 点击固定按钮。
固定之后,你可以在任意普通网页上直接点击 DataLens 图标打开侧边栏。
第三步:打开并登录
- 打开你想采集的网页。
- 点击浏览器工具栏里的 DataLens 图标。
- 如果提示登录,按页面提示完成登录。
- 登录后回到目标网页,按侧边栏提示进入当前页面的采集流程。
DataLens 会读取当前活跃标签页,并在侧边栏里进入表格或列表检测。
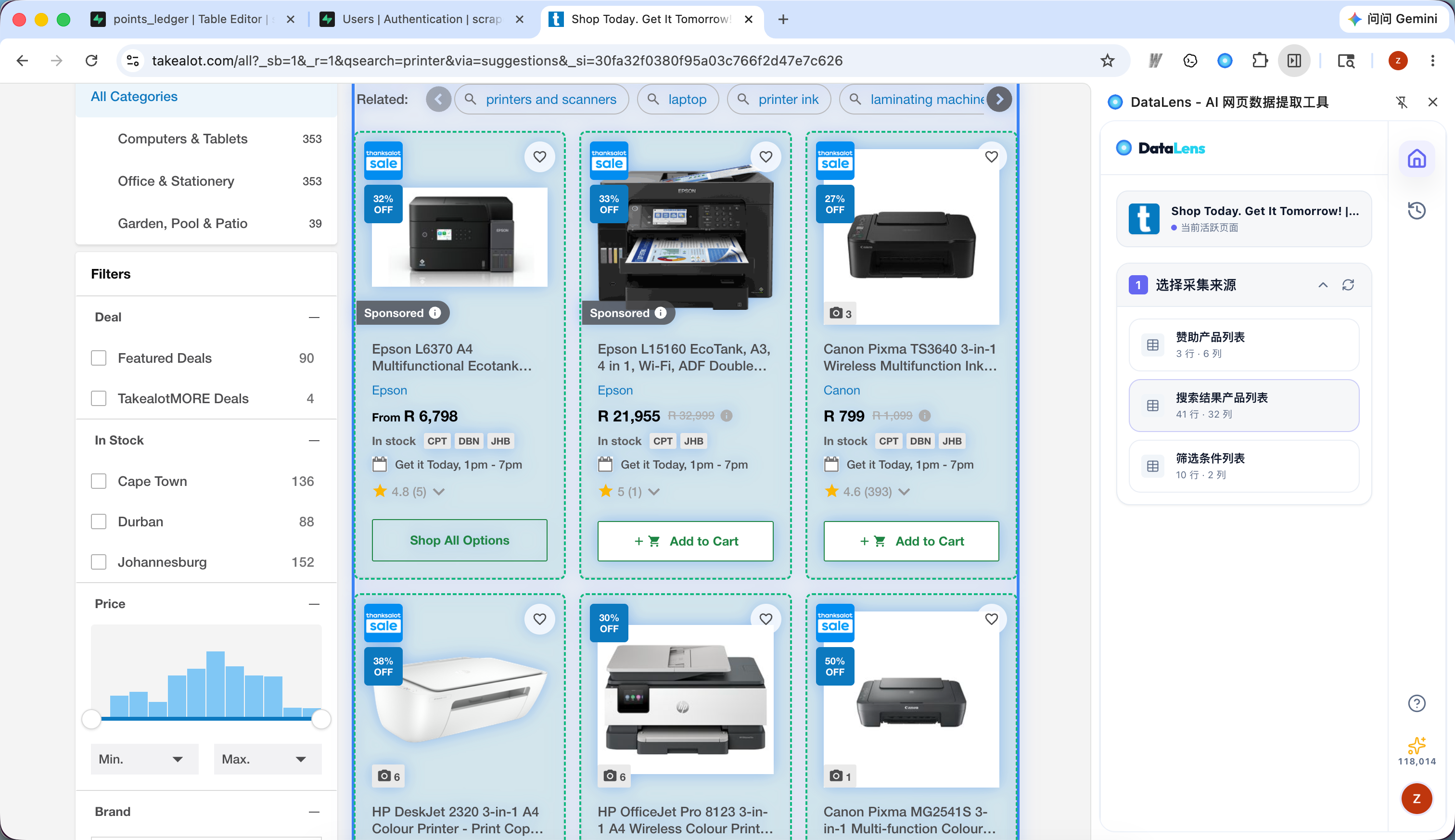
1.2 三步完成一次采集
步骤一:选择采集来源
DataLens 会自动检测页面上的表格或列表结构。你会看到一个候选列表,每个候选项会显示大概行数和列数。
操作方式:
- 把鼠标移到候选项上,网页里的对应区域会高亮。
- 选择你真正想采集的那一块数据。
- 如果识别不准,点击重新检测。
选择后,DataLens 会进入字段分析。
步骤二:字段编辑
DataLens 会用 AI 识别字段,例如标题、价格、评分、链接、图片、发布时间等。
你可以做这些调整:
- 删除不需要的字段。
- 保留需要导出的字段。
- 检查字段示例值是否符合预期。
- 把鼠标移到字段上,查看网页里对应的识别位置。
- 双击字段名称,改成你更容易理解的名字。
- 设置采集条数限制。
确认字段后,点击“开始采集”。
步骤三:配置详情页下钻采集(可选)
如果你要采集的数据不在列表页,而是在每一行点进去后的详情页,例如:
- 商品详情、规格、长描述
- 文章正文、作者信息
- 招聘详情、公司介绍、岗位要求
- 商家详情、地址、联系方式
这种情况下才需要配置下钻采集。如果列表页已经包含你需要的全部字段,可以跳过这一步,直接开始采集。
操作方式:
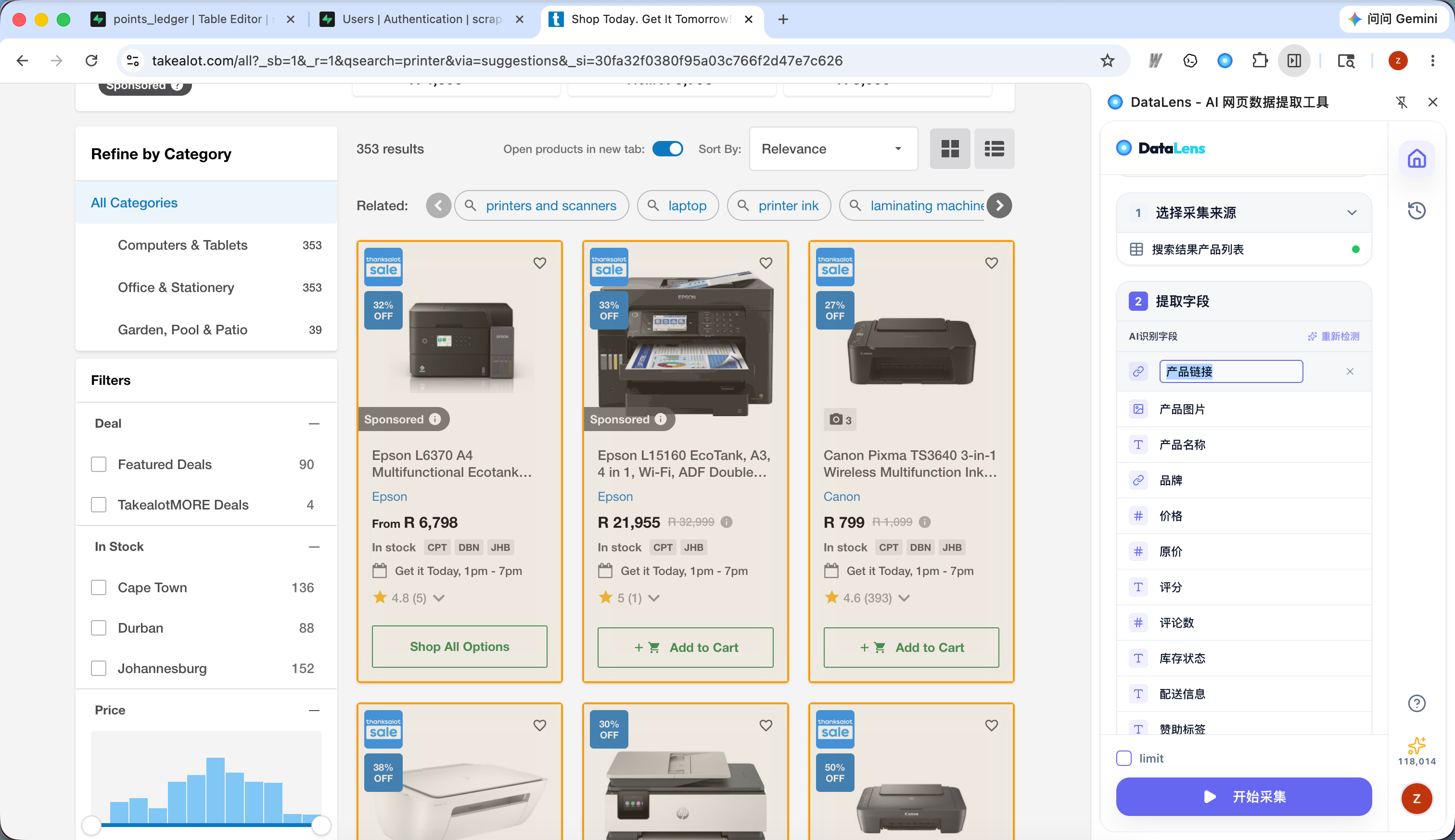
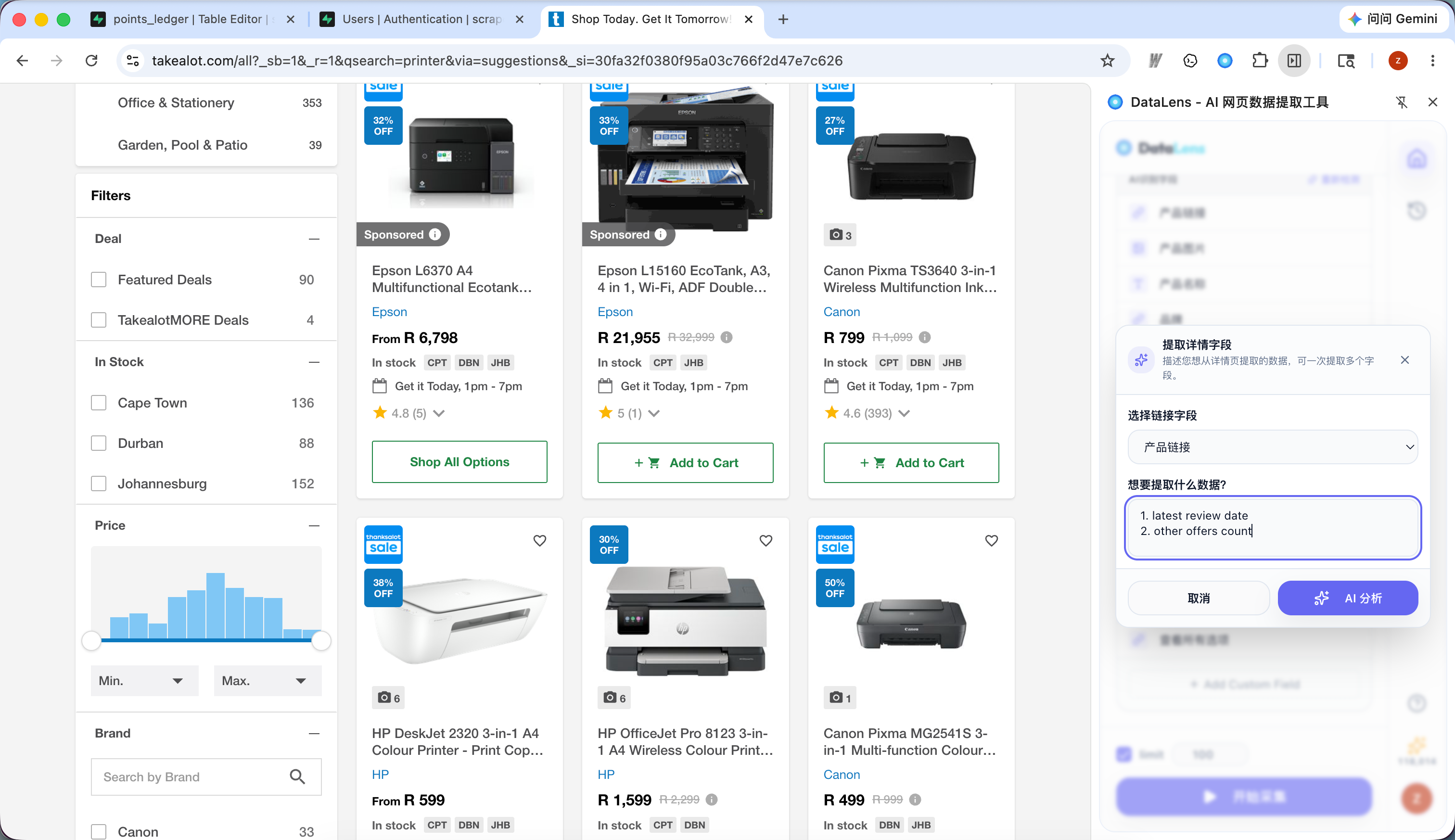
- 在字段编辑页点击“提取详情字段”。
- 选择一个能打开详情页的链接字段。
- 输入你想从详情页提取的内容,例如“商品价格、详细描述和规格参数”。
- 点击“AI 分析”。
- 检查识别出的详情字段,删除不需要的字段。
- 如果字段不符合预期,点击返回,修改成更精准的需求描述后重试。
- 点击“确认”,再开始采集。
配置下钻后,DataLens 会先采集列表页,再逐条打开详情页提取补充字段。
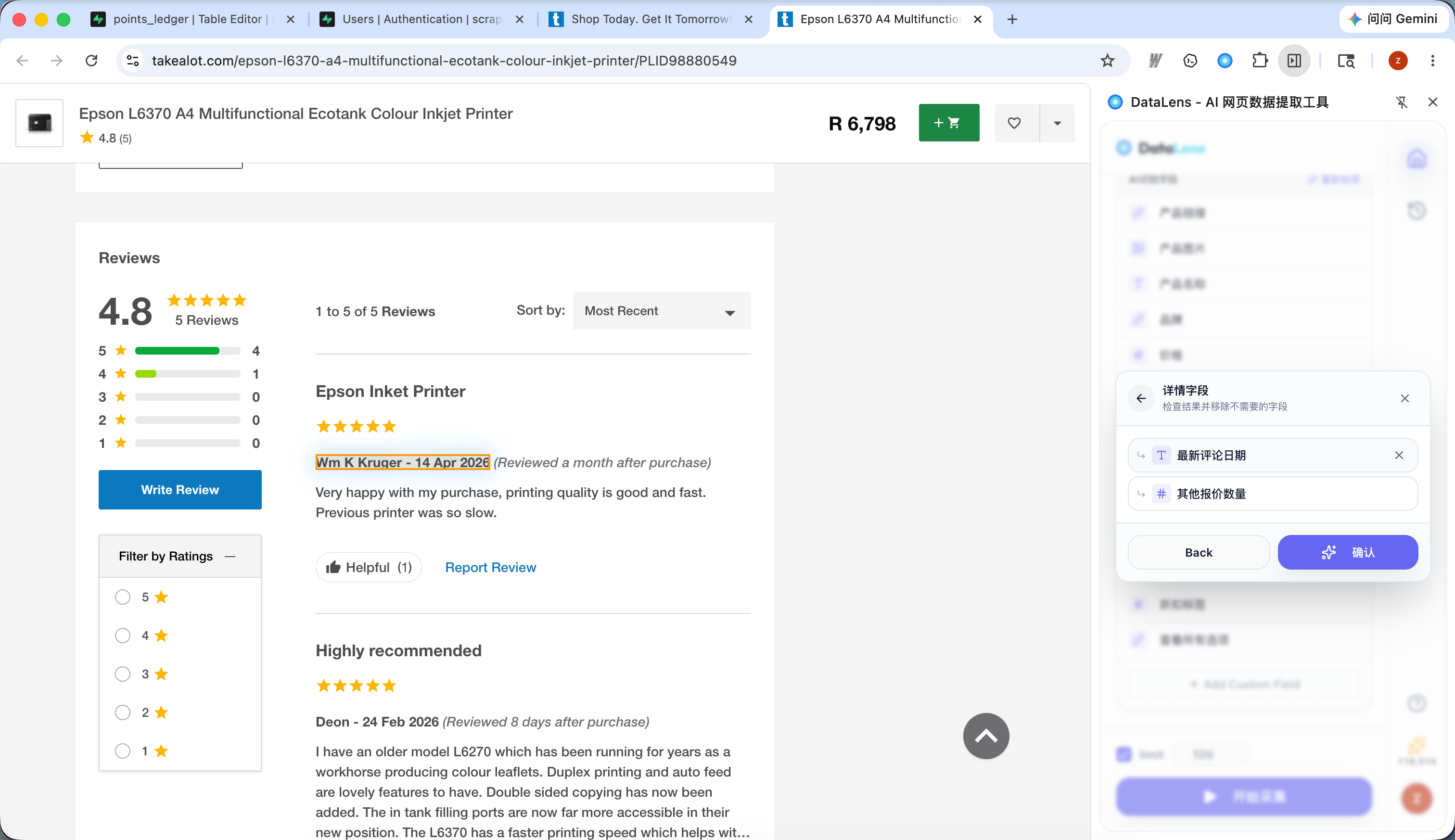
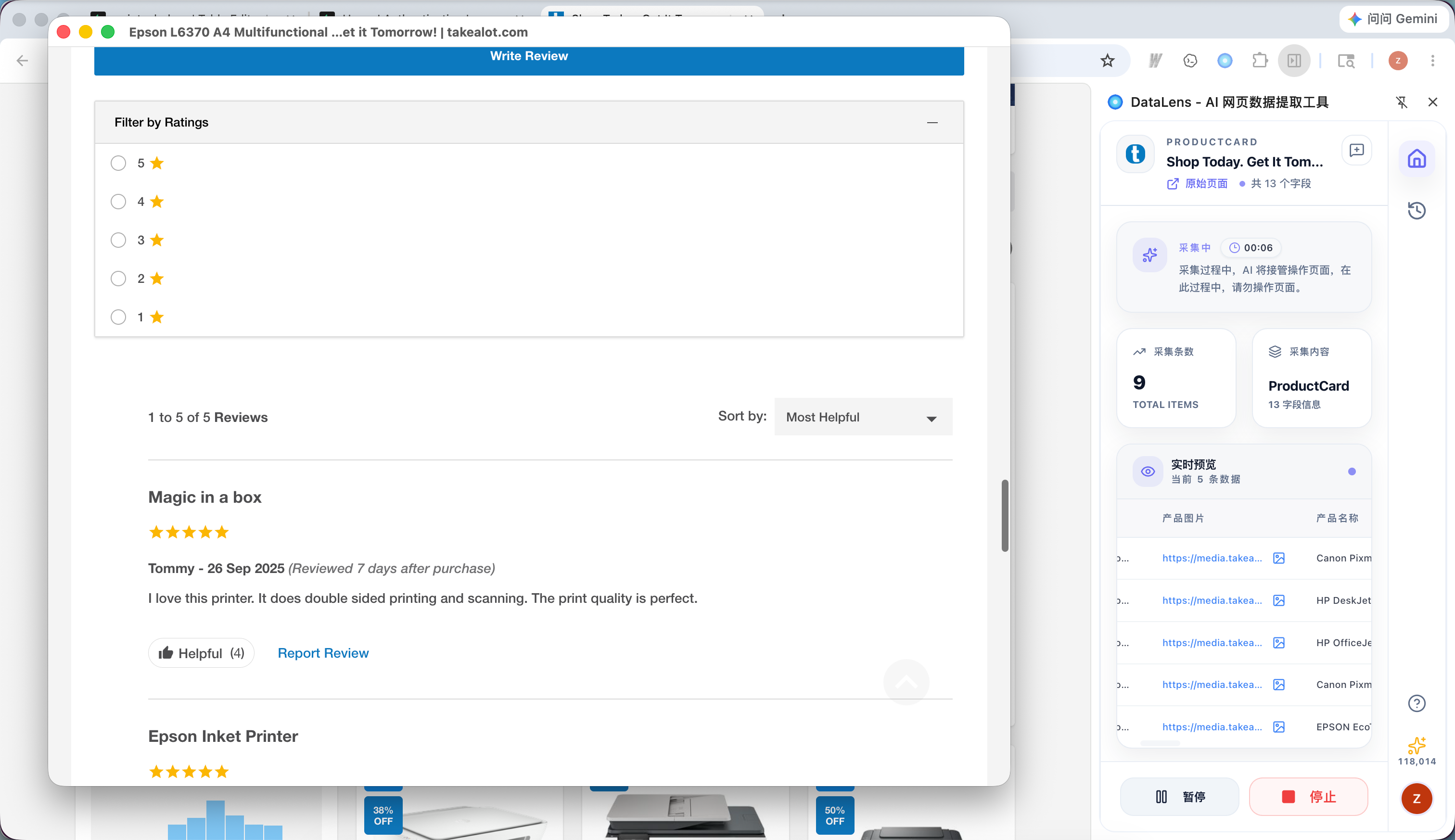
1.3 查看、下载数据和批量下载图片
采集运行时,侧边栏会显示当前状态、采集条数、字段数量和实时预览。采集完成后,你可以在预览页下载数据,也可以在历史记录中查看已完成任务。
下载结构化数据
你可以在采集完成页、历史详情页或预览页下载数据。
支持格式:
- Excel:
.xlsx - CSV:
.csv - JSON:
.json
如果你只是要在 Excel 或 Google Sheets 里查看,优先下载 Excel 或 CSV。
如果你要交给程序或后续系统处理,优先下载 JSON。
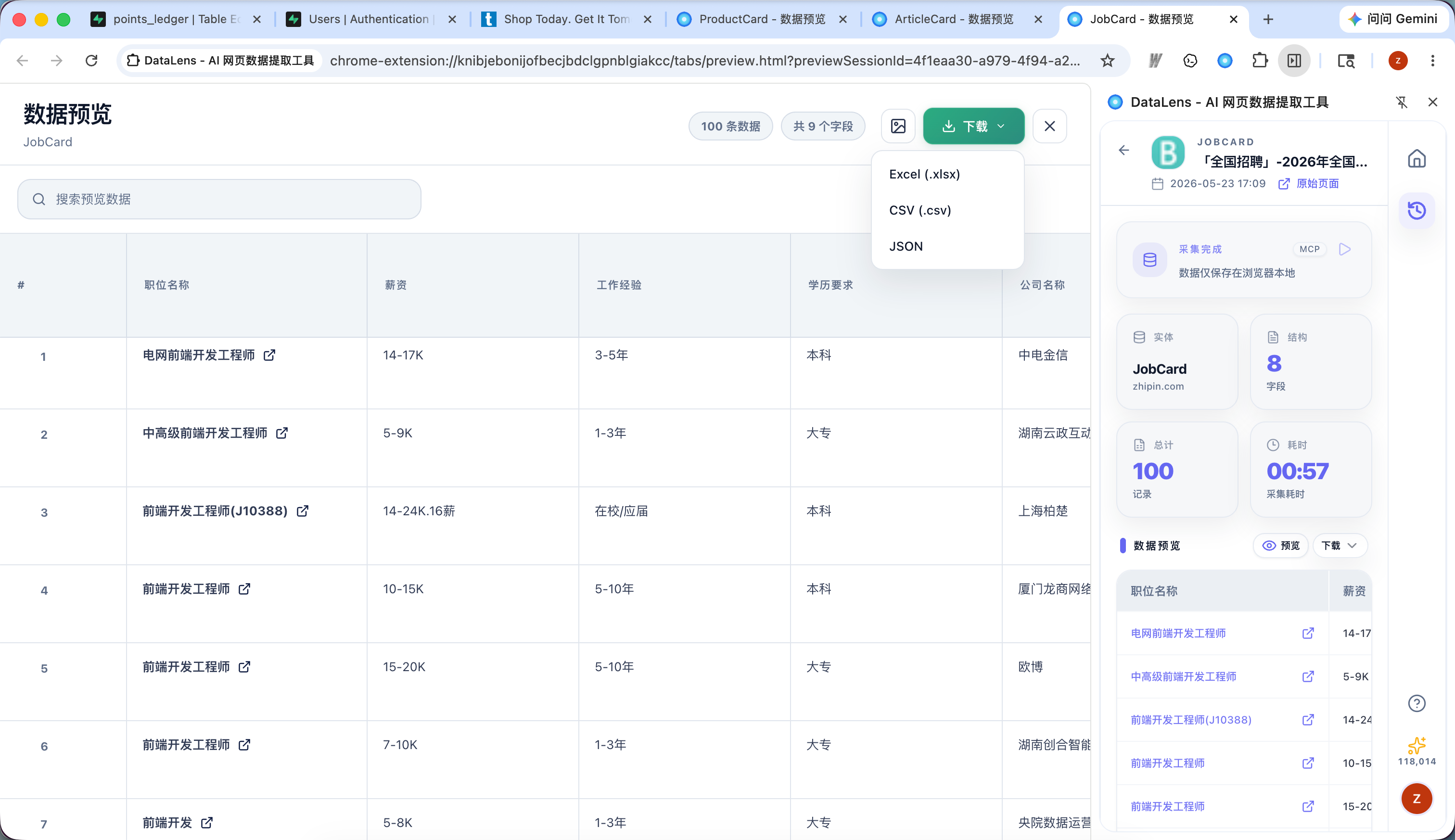
批量下载图片
如果采集结果里有图片字段:
- 打开数据预览页。
- 找到图片列。
- 点击图片列标题旁边的下载图标。
- 选择保存位置。
- 等待图片下载完成。
预览页会显示图片下载进度,也可以把下载任务放到后台继续。
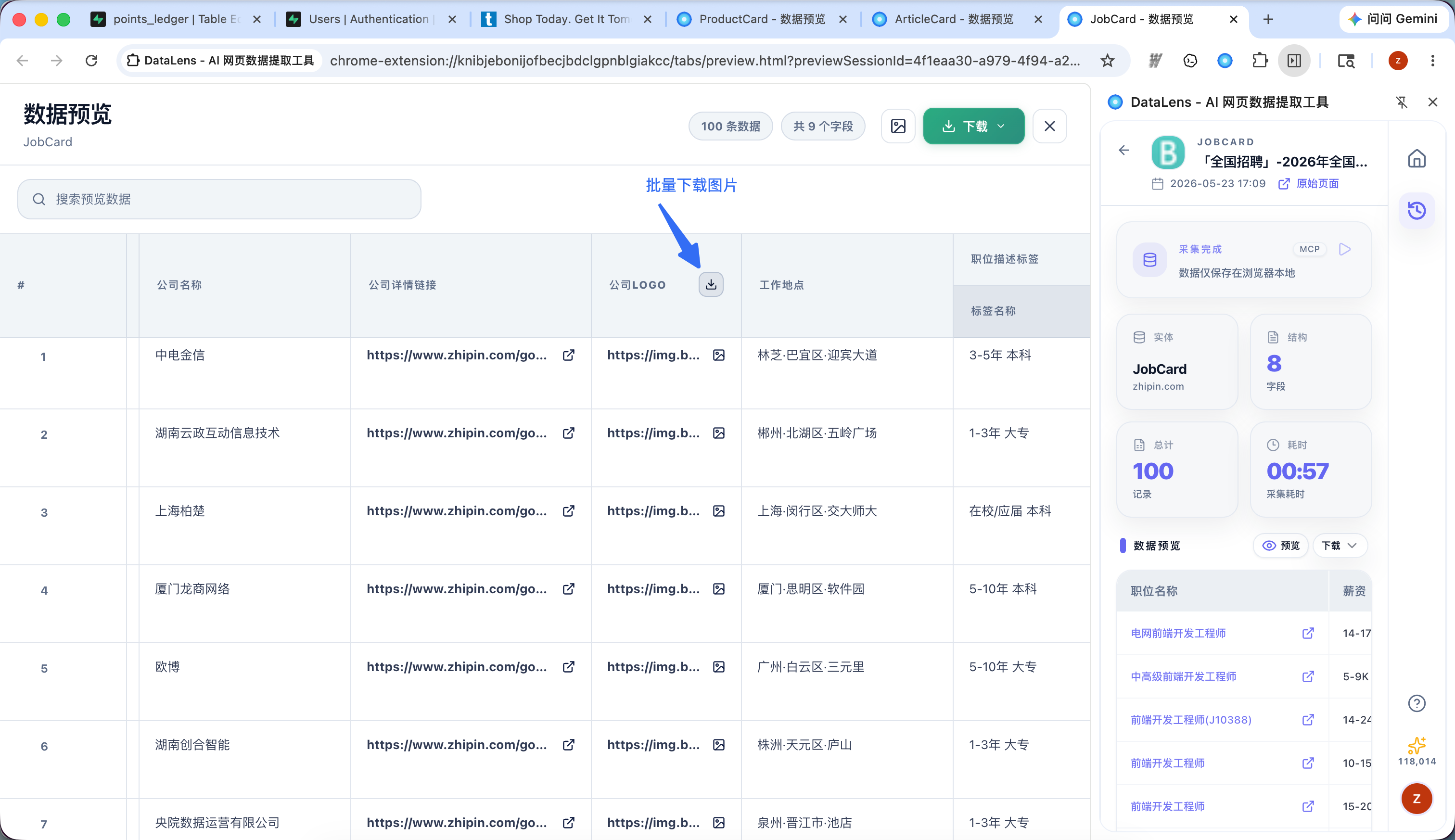
1.4 亮点能力
识别加密或混淆字段
一些网站会用特殊字体或页面渲染方式展示字段,例如 BOSS 直聘薪资、淘宝商品价格等。只要这些内容已经在你的浏览器页面中正常展示,DataLens 会自动识别并还原为可导出的文本字段。
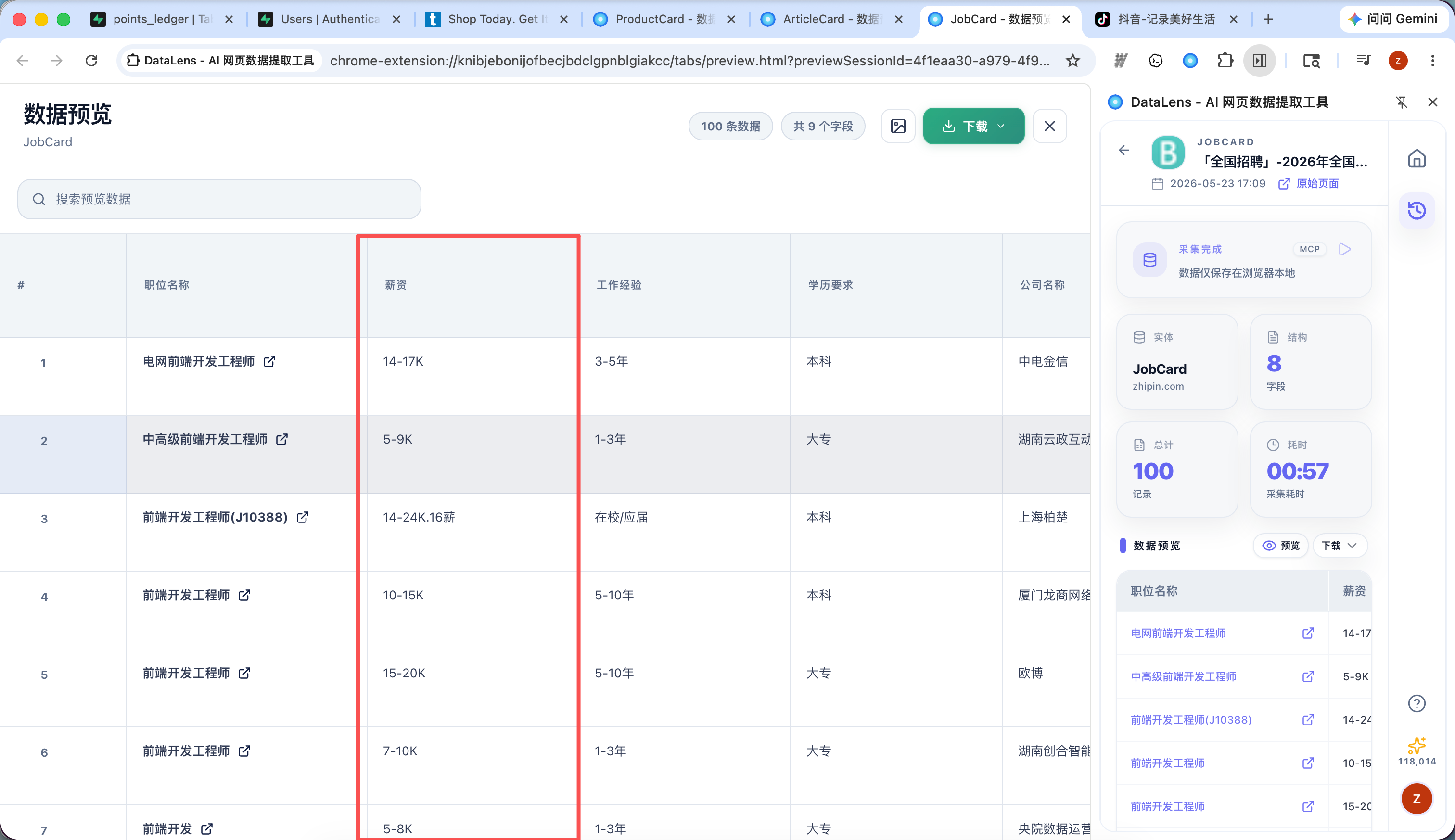
自动处理嵌套评论和展开按钮
对于抖音评论、社区讨论、帖子回复这类场景,DataLens 可以识别主评论、子评论和展开按钮。采集时会自动展开可见的评论结构,并把子评论整理进结果中。
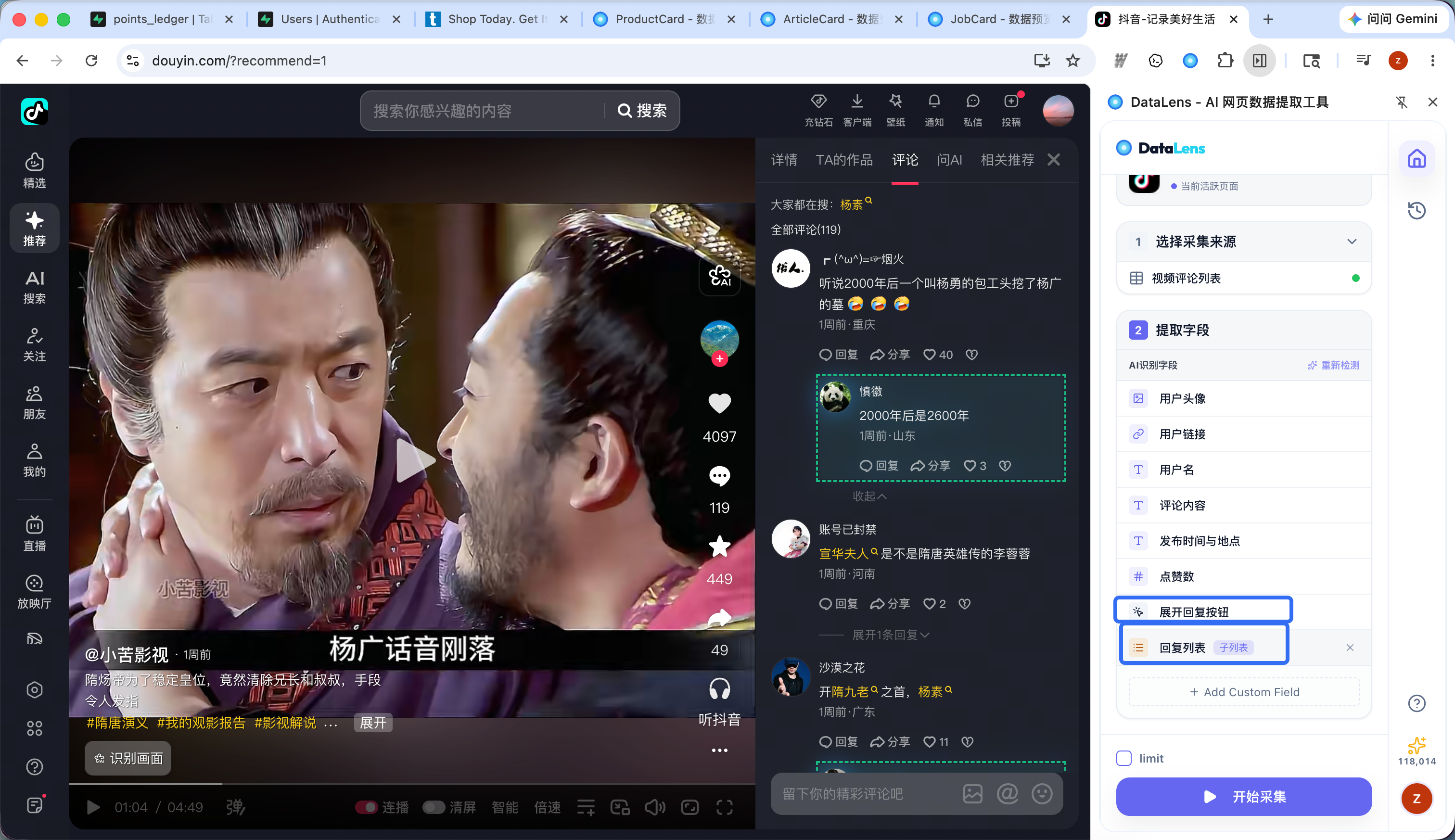
从详情页扩展更多字段
下钻采集适合从列表页进入详情页补充更多字段。比如列表页只有标题、价格和链接,详情页里还有完整描述、规格参数、公司介绍、正文内容等,DataLens 可以把这些详情字段合并到同一份结果里。
1.5 插件采集示例
假设你要采集一个电商搜索结果页里的商品信息:
目标:采集前 100 个商品的标题、价格、评分、评论数、图片和详情页描述。
操作流程:
- 打开商品搜索结果页。
- 点击浏览器工具栏里的 DataLens 图标。
- 登录后按侧边栏提示进入当前页面的采集流程。
- 在“选择采集来源”里选择商品列表。
- 在字段编辑页保留标题、价格、评分、评论数、图片、商品链接。
- 点击“提取详情字段”,选择商品链接字段,输入“提取商品详情页里的完整描述和规格参数”。
- 检查详情字段后确认。
- 设置 limit 为 100。
- 点击“开始采集”。
- 采集完成后下载 Excel;如果需要商品图片,在预览页点击图片列的下载图标批量保存。
2. Chat Agent:用自然语言完成采集、分析和报告
Chat Agent 适合把一整套数据任务交给 DataLens:打开网页、识别采集目标、采集数据、整理结果、生成报告和可下载文件。
2.1 如何提出一个明确需求
一个好的需求最好包含 5 个信息:
- 目标网页:要采集的网址。
- 采集对象:商品、评论、文章、招聘、商家、视频、帖子等。
- 字段要求:要哪些字段,不要哪些字段。
- 数量范围:例如前 50 条、前 200 条、当前页全部可见数据。
- 后续产物:是否要清洗数据、分析、图表、Markdown 报告、CSV 或 Excel 文件。
推荐写法:
请打开这个页面:https://example.com/search?q=coffee
采集前 100 条商品数据,包括标题、价格、评分、评论数、商品链接和图片。
如果每个商品详情页里有描述和规格,请进入详情页提取。
采集完成后,分析价格分布和评分分布,生成一份报告,并保存清洗后的 CSV。
不推荐写法:
请帮我采集全网热销商品。
这个说法范围太大,也缺少目标网站、目标字段、数量范围、是否下钻和产物要求,Agent 很难直接开始采集。
2.2 Chat Agent 的典型工作流
一次完整任务通常会经过这些阶段:
- 打开目标网页。
- 检查页面结构,必要时点击筛选、搜索、分页或加载更多。
- 检测可采集的表格或列表。
- 分析字段结构。
- 如果你要求详情页字段,配置下钻采集。
- 启动采集任务。
- 采集完成后保存结果。
- 整理当前任务生成的数据文件。
- 按你的要求完成清洗、合并、统计、图表或报告。
- 把生成的文件展示在文件面板中,供你预览和下载。
如果目标网站需要登录,Agent 不会向你索要密码,也不会绕过权限。它会提示你在浏览器里自己完成登录,然后再继续采集。
2.3 如何采集、分析和生成报告
你可以把采集和分析写在同一条消息里:
打开 https://example.com/jobs?q=data
采集前 80 条招聘信息:职位名称、公司、地点、薪资、发布日期、职位链接。
进入每条职位详情页,提取岗位职责、任职要求和公司介绍。
采集完成后分析:
1. 哪些城市机会最多
2. 薪资区间分布
3. 高频技能关键词
4. 值得关注的岗位清单
最后生成一份 Markdown 报告,并保存清洗后的 CSV。
你也可以分步做:
先采集这个页面前 50 条数据,只保留标题、链接、发布时间和摘要。
采集完成后再说:
基于刚才采集的数据,帮我分析主题分布,生成一份中文报告。
2.4 产物如何查看和下载
Chat 里有两类产物:
采集结果
采集完成后,结果卡片可以打开预览面板。预览面板里可以下载 Excel 采集结果。
工作台文件
当 Agent 生成了清洗数据、分析表、图表或报告,这些文件会出现在右侧文件面板中。
常见文件类型:
- 原始数据:采集得到的 CSV。
- 清洗数据:处理后的 CSV。
- 分析产物:统计表、图表图片等。
- 报告:Markdown 报告或其他报告文件。
下载方式:
- 打开右侧文件面板。
- 点击文件查看预览。
- 点击下载按钮保存文件。
如果 Agent 在回复中给出 @文件名 形式的文件链接,也可以直接点击该文件链接打开预览。
2.5 Chat Agent 是如何工作的
你可以把 Chat Agent 理解成三层:
第一层:浏览器操作
Agent 通过 DataLens 浏览器插件打开目标网页、读取页面结构、点击筛选项、检测列表或表格,并启动采集任务。
实际采集由 DataLens 自动完成,不是手动一条条复制网页内容。这样可以处理滚动、分页、加载更多和详情页下钻。
第二层:数据采集
DataLens 会根据字段配置执行采集。对于普通列表,它采集列表页字段;对于详情页字段,它会基于链接字段打开每条记录的详情页,再补充详情字段。
采集完成后,结果会出现在当前对话中,并可以继续用于分析和报告。
第三层:数据分析与报告
当你要求分析、清洗、合并、图表或报告时,Agent 会基于已采集的数据生成新的文件。你不需要自己写代码;只需要说明想看哪些结论、图表或报告。
3. 选择哪种方式
使用浏览器插件,当你:
- 想自己确认页面上哪一块数据被采集。
- 想手动编辑字段。
- 想快速从当前页面导出 Excel、CSV 或 JSON。
- 想批量下载图片列里的图片。
使用 Chat Agent,当你:
- 希望用一句话完成采集、清洗、分析和报告。
- 需要详情页字段,但不想手动配置每一步。
- 需要对多个文件做合并、统计或图表。
- 需要让 Agent 生成可下载的报告和分析产物。
4. 常见问题
为什么 Chat Agent 提示要安装或更新插件?
Chat Agent 的网页采集能力依赖 DataLens 浏览器插件。如果插件不可用,Agent 会停止调用浏览器采集工具,并提示你安装、更新或刷新插件。
为什么页面检测不到表格?
可能原因:
- 当前不是普通网页,例如浏览器设置页、扩展页、空白页。
- 页面还没加载完。
- 数据需要先搜索、筛选、滚动或展开。
- 页面结构比较特殊,需要 Agent 通过页面结构兜底识别。
你可以先刷新页面,再重新检测;或者在 Chat 里告诉 Agent:“先点击某个筛选/搜索/加载更多,再采集列表”。
什么时候需要下钻采集?
只有当目标字段不在列表页,而在每条记录点进去后的详情页时,才需要下钻采集。
例如列表页只有商品标题和价格,但你还要商品详情描述,就需要选择商品链接字段并配置详情字段。
下载 Excel、CSV、JSON 怎么选?
- Excel:适合人工查看和简单分析。
- CSV:适合表格软件、BI 工具、数据库导入。
- JSON:适合程序处理,能保留更复杂的结构。
采集时还能操作网页吗?
不建议。采集过程中 DataLens 会自动滚动、翻页或打开详情页。为避免影响结果,建议暂时不要操作目标网页。
使用 DataLens 需要注意什么?
请确保你有权访问和使用目标网页上的数据,并遵守目标网站的服务条款、隐私政策和当地法律法规。不要采集你无权访问的数据,也不要用 DataLens 绕过登录、付费、验证码或其他访问限制。